为了评估ReL4的兼容性,我们在ReL4上成功运行了seL4test并通过了相关的测试用例,而为了评估异步IPC和异步系统调用的效率,我们在ReL4上对比了不同负载下异步IPC和同步IPC的性能,最后构建了一个高并发的TCP Server和内存分配器用于评估异步IPC和异步系统调用在真实应用中的表现。实验环境配置参数下表所示。
| 环境 | 配置 | |
|---|---|---|
| FPGA | Zynq UltraScale + XCZU15EG-2FFVB1156 MPSoC[31] | |
| RISC-V 软IP核 | rocket-chip[30] with N extension, 4 Core, 100MHz | |
| 以太网IP核 | Xilinx AXI 1G/2.5G Ethernet Subsystem (1Gbps)[32] | |
| 操作系统 | ReL4 | |
| 网络协议栈 | smoltcp[33] |
1. 内存分配服务器 #
为了验证异步系统调用对于系统性能的影响,我们在用户态设计了一个用于内存分配的服务器,该服务器线程通过消息队列不断接收其他线程发送的内存分配/释放请求,调用map/unmap系统调用处理请求并返回响应。我们用同步和异步的方式分别实现了系统调用的处理流程,结果下图所示,横坐标为服务器中的协程并发数,左侧纵坐标为单个系统调用的占用的平均CPU周期数,右侧纵坐标为系统调用陷入内核的频率,同步系统调用的频率为1。
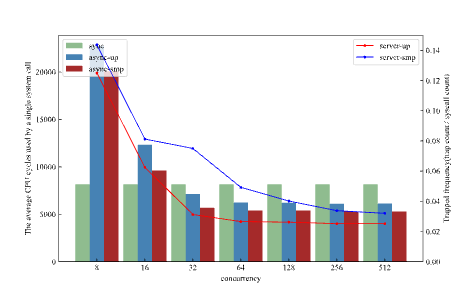
从总体趋势上看,异步实现的内存分配器的性能随着并发度的提高,性能呈稳步上升的趋势,在并发度为64之后趋于稳定,这是由于并发度提升,内核陷入频率降低,特权级切换开销下降,导致了性能的提升。
同步和异步的对比来看,当并发度小于32时,同步系统调用的性能仍然高于异步系统调用,这是由于异步系统调用除了陷入内核的开销之外,还有运行时的开销以及U-notification的开销,因此在并发度较低时,减少的特权级切换开销少于增加的额外开销,因此异步系统调用性能较低。当并发度高于32后,特权级的切换开销急剧下降,因此异步的系统调用性能超过了同步IPC,与异步IPC相似,当内核负载增加时,客户端陷入内核的频率也会逐渐下降,直至降为0。
单核与多核对比来看,当内核与客户端不在同一个CPU核心上时,系统调用请求与处理将并行处理,因此性能会优于单核,但由于此时内核独占一个CPU核心,内核负载较小,客户端陷入内核的频率会略高于单核。
2. 同步IPC vs. 异步IPC #
为了从微观角度评估我们设计的异步IPC性能,我们测量了不同并发量和不同服务端负载下异步IPC和同步IPC的平均开销。由于我们关注的是同步IPC和异步IPC的路径差异,需要保证场景没有过多干扰,因此我们分别构建了一个服务端进程和一个客户端进程进行乒乓测试,测试结果如下图所示。
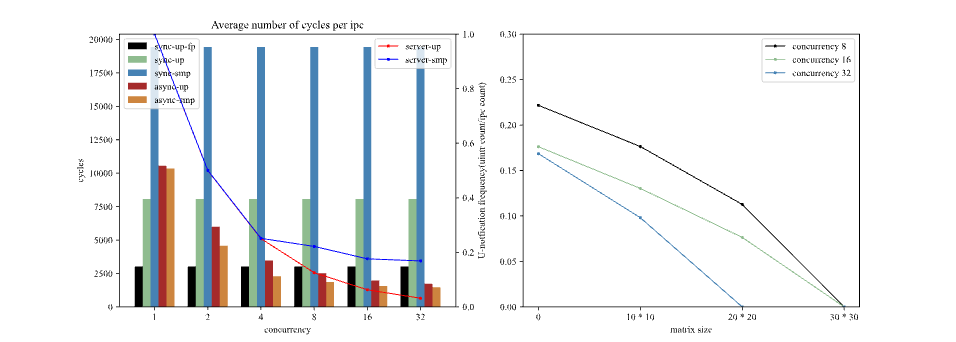
由于同步IPC会阻塞整个线程,因此并发量对同步IPC并没有意义。而在多核环境下,fast-path检查会失败,所有的同步IPC都会在内核中通过核间中断进行传递,因此多核环境下的同步IPC性能很低;而对于单核下的同步IPC,fast-path会避开复杂的消息解码和冗长的调度流程,因此开启fast-path的IPC性能会提升167%,但我们需要注意的是,fast-path对于线程优先级、消息长度等有着严苛的检查流程,因此在实际应用场景中fast-path优化并不总能生效。
我们从横向的角度分析异步IPC,发现异步IPC的开销随着并发量的提升而降低,这是由于随着并发量的增加,服务端的负载进一步增加,而U-notification的通知时机采用自适应的形式,因此通知频率下降,导致了均摊到每个IPC的开销下降。我们还可以看出,在并发度较小的时候,多核会略快于单核(最高提升52%),符合预期,随着并发度的逐渐增加,多核与单核的性能差异逐渐缩小(17%),这是由于多核情况下服务端单独使用一个CPU核心,导致服务端负载过小,产生了更加频繁的用户态中断(如左图中的蓝色折线),导致服务端吞吐量过小,又反过来限制了客户端的请求频率。可以从第二幅图中看出,当我们增加服务端负载时,服务端的中断频率会逐渐下降,直至归0,这是自适应轮询带来的优势。
对比同步IPC和异步IPC,当并发度为1的时候,每个异步IPC的开销都包含了两次用户态中断的开销、调度器的运行时开销,而同步IPC则是两次特权级切换的开销,如果没有fast-path优化,还会有内核路径中的解码开销和调度开销,因此在低并发度的场景下异步IPC的性能会略低于没有fast-path优化的同步IPC(31%),同时显著低于有fast-path优化的同步IPC(249%)。而当并发量较大时,用户态中断的频率减少,均摊到每一次IPC下,用户态中断的开销几乎可以忽略不计,因此异步IPC的开销主要是调度器的运行时开销,而此时的异步IPC性能会显著高于没有fast-path优化的同步IPC(369%),也高于有fast-path优化的同步IPC(76%)。
从上面我们可以得出结论:在多核场景下,我们的异步IPC相比于同步始终有着良好的表现。而在单核且低并发度场景下,异步IPC性能会比较差,但随着并发度增加,异步IPC的性能会迅速提升,在并发度为2时就已经超过没有fast-path优化的同步IPC,在并发度为8时就已经超过了开启fast-path优化的同步IPC,因此异步IPC依然十分有竞争力。
3. TCP 服务器 #
为了测试异步IPC在真实应用场景带来的收益,我们在ReL4上实现了一个TCP服务器。模拟的TCP服务器应用场景由三部分组成,一部分是运行在PC上的客户端,它在启动时与运行在FPGA上的TCP Server建立若干个连接,并不断地向服务端发送64字节(小包)的数据,并接收服务器的响应;第二部分是运行在ReL4上的网络协议栈服务器(NW Stack Server),集成了网卡驱动的代码,并通过smoltcp协议栈维护每个连接的状态信息,负责从网卡中接收数据并进行协议处理后通过共享内存返回给TCP Server,以及从TCP Server接收数据并通过网卡发出;第三部分是TCP Server,它以IPC的形式从NW Stack Server接收客户端发送过来的请求,在处理完成之后返回响应并通过NW Stack Server发送给客户端。最后,PC 上的客户端计算发送每个请求和接收响应之间的时间延迟,并计算固定时间段内的消息吞吐量。我们通过分析不同配置下 TCP Server 的时间延迟和吞吐量来评估 ReL4。需要注意的是,由于同步IPC的无法支持多路复用,因此同步IPC下每个连接都使用单独的线程来监听。测试结果如下图所示。
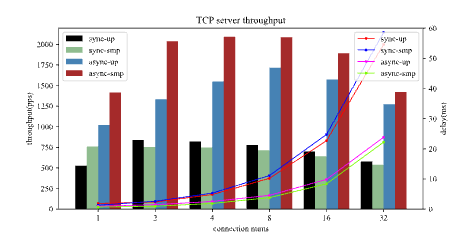
从总体趋势上看,吞吐量随着并发度的增加呈现先增加后减少的趋势,而时延成整体上升的趋势。在低并发度条件下的系统负载处于较低水平,随着并发度增加,吞吐量能稳步提升,随着系统满载之后,继续增加并发度,会导致网络中断频率上升,从而限制系统的整体性能,吞吐量减少。
同步和异步对比来看,可以看出当连接数较低,并发度较小的情况下,异步IPC实现的TCP Server无论是在吞吐率还是平均时延上都要优于同步IPC,这是由于同步IPC需要频繁陷入内核,而由于微内核不可被抢占的设计,内核态屏蔽了网络中断,导致网络包无法及时处理。而随着并发度的增加,由于同步IPC实现的TCP Server需要多线程来保证多连接,因此线程切换的开销急剧加大,导致同步和异步的差距进一步增加。在连接数为4的时候差距达到最大,为192%,在并发度最大的情况下,异步IPC实现的TCP Server也比同步IPC高出120%。
单核与多核对比来看,异步IPC实现的TCP Server随着CPU资源增加,吞吐量提升,时延降低,而对于同步IPC实现的TCP Server情况则有所不同,由于同步IPC在多核下采用的IPI的形式在内核进行转发,导致程序的内存局部性和代码局部性都不够友好,因此多核的性能变现会略低于单核。
从上面我们可以得出结论:异步IPC在实际应用场景中有利于多路复用的实现,可以有效减少特权级切换的开销,提升系统的整体性能。