这主要分为两篇文章: Response-Time Analysis of ROS 2 Processing Chains Under Reservation-Based Scheduling(ECRTS 19’) Automatic Latency Management for ROS 2: Benefits, Challenges, and Open Problems(RTAS 21’)
Response-Time Analysis of ROS 2 Processing Chains Under Reservation-Based Scheduling #
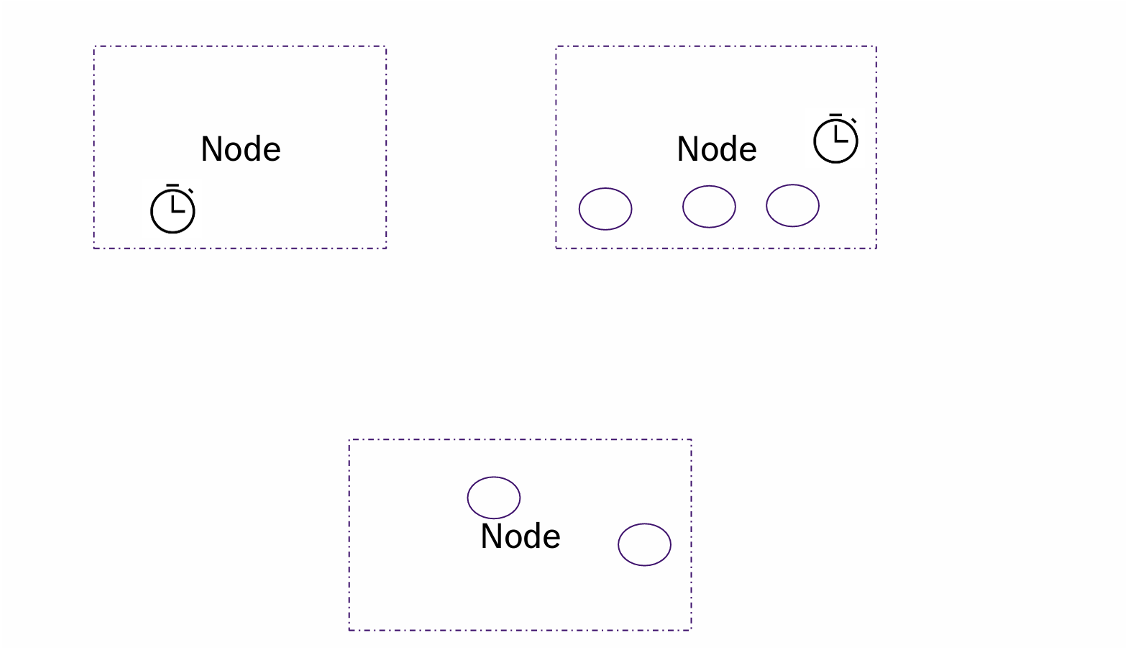
先来说ROS本身的模型
系统中有若干个node,每个node里面都有若干个个callback回调函数
ROS 通信方式 #
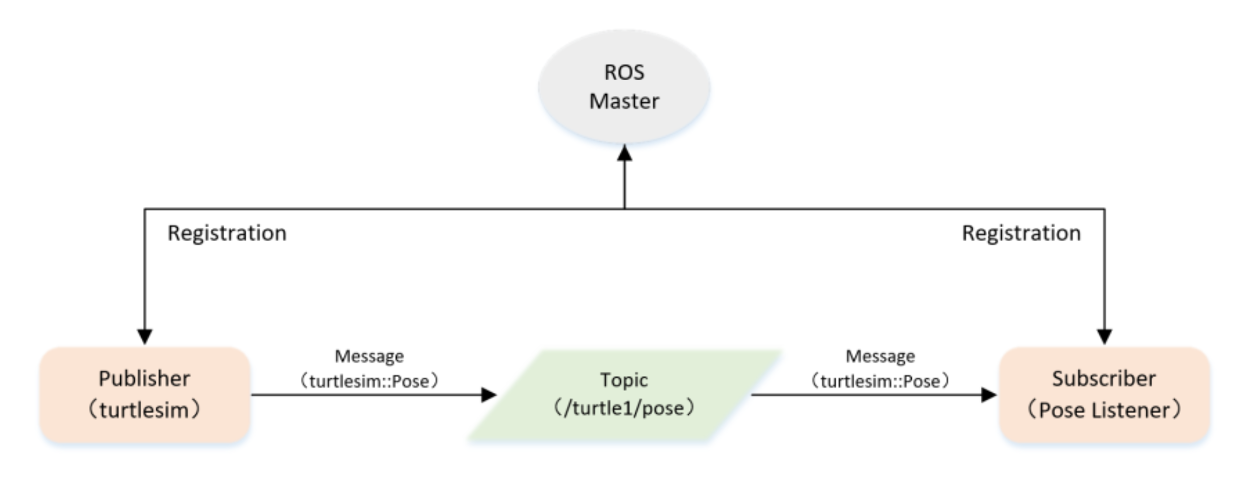
这些callback之间通信的方式,第一种是使用topic的发布订阅方式
Publisher向Master注册。
Subscriber也向Master注册。
然后当publisher试图发布消息的时候,发布一个topic
经由Master转发之后
所有订阅了这个topic的subscriber都会收到这个消息。 (但是ROS本身是可能分布式的,通过网络通信的,所以这一步会引入传递时延。)
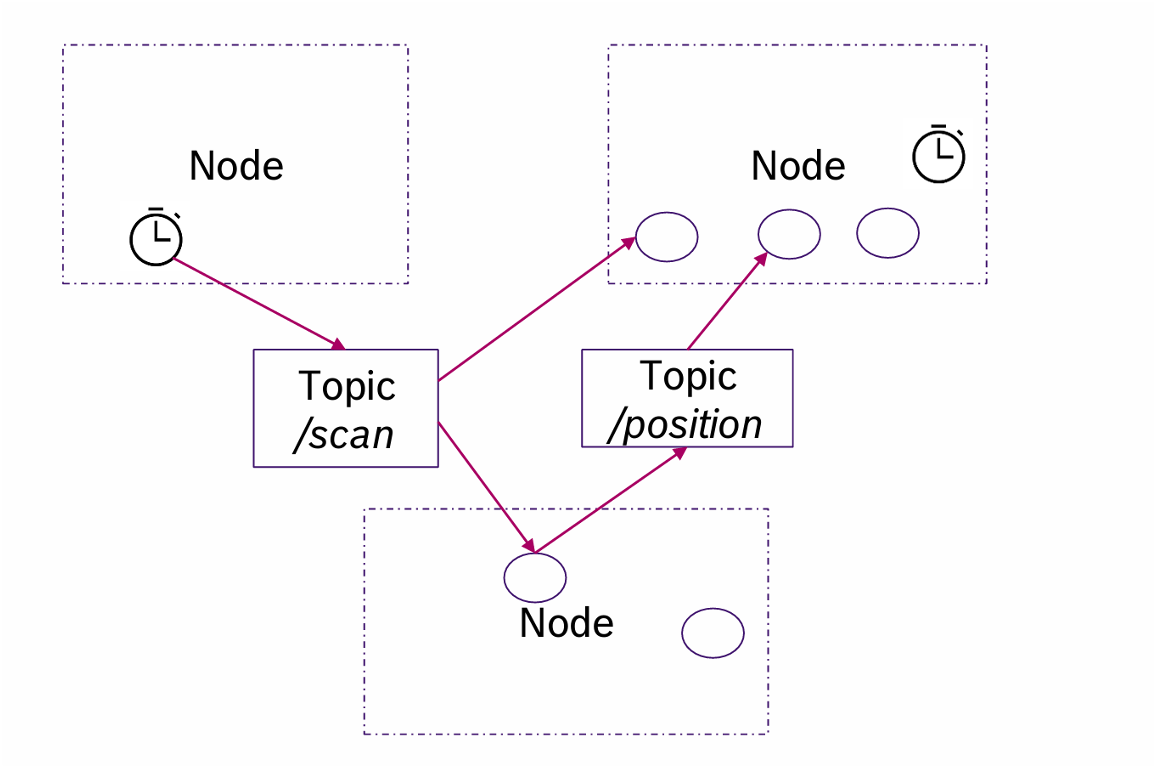
 在模型中我们可以不考虑Master节点的影响,从而模型变成一个有向无环图(DAG)
在模型中我们可以不考虑Master节点的影响,从而模型变成一个有向无环图(DAG)
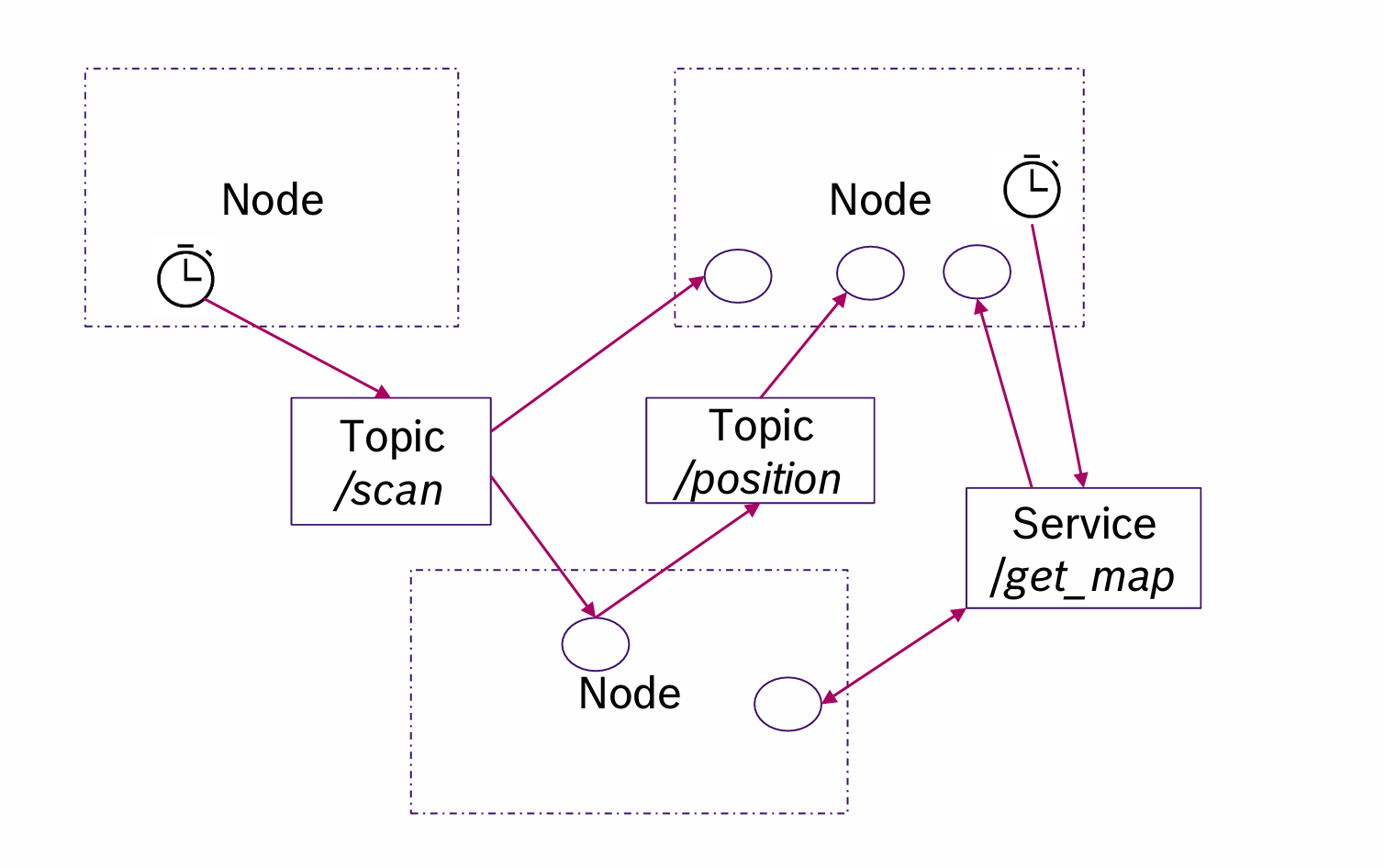
除了发布订阅之外的另一种通信方式,还有service,这是一个同步的方式(但是跟我们的分析没啥关系)
ROS node到进程的关系 #
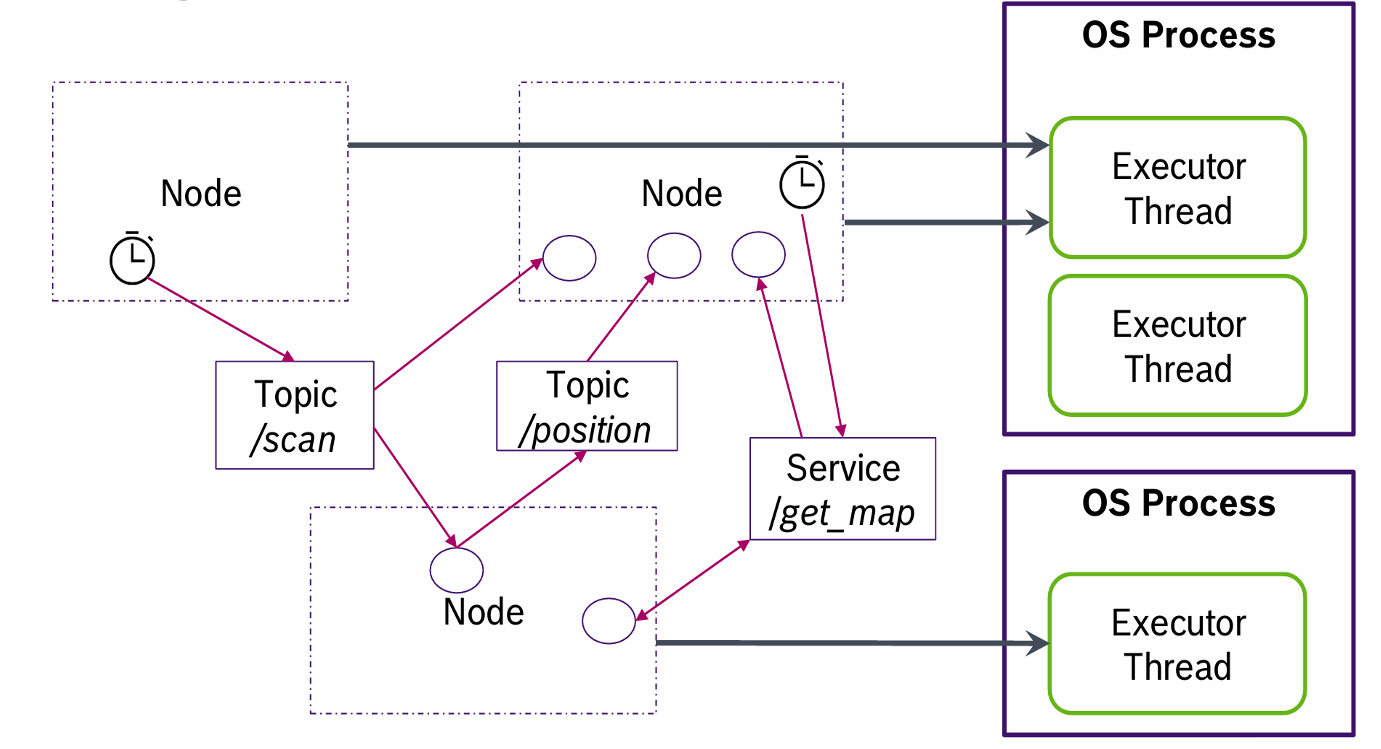
上述这些概念和操作系统中的进程线程之间的关系如下图这个映射,一个包含了若干个callback的node会被映射到操作系统中的某个executor thread上。
- 对实时的影响:
由于ROS本身是一个用户态的程序,所以他的某个node的callback何时被调度出来执行,一方面取决于本身的pp-based的(后面会说)的调度策略,另一方面也取决于OS层面对不同node的调度
ROS在OS层面的调度采用Linux的SCHED DEADLINE(其实就是EDF调度器)
ROS调度模型 #
- PP(polling point)-based的ROS调度方式
这个层面的调度针对的内容是callback。上一页ppt中的OS层面的调度主要是针对于executor的线程之间的调度。而这个PP调度,是针对于一个executor中的一堆callback的执行的
- 就绪集(Ready Set)
已经到达了,但是还没有处理的callback的集合
什么是PP-based schedule
首先他是非抢占的(用户态的ROS也不好做抢占),每当他变成idle,就去查询DDS通信层的快照消息,把所有可能的任务都塞进来,更新就绪集。(这就是一个polling point)。然后在polling point,尝试着调度其他callback。
说人话,就是每次从DDS拉取一堆任务过来,非抢占的一个一个执行。
- Callback的类型: 1/timer
2/subscribers
3/services
4/clients
但是在ROS的response 分析中被分为两类
Timer:定时器callback的调度不受polling point影响。当定时器触发时,它会立即被调度执行(这个意思是,他会插队进来,放到当前执行的callback的后面),而无需等待下一个轮询点。但是因为他是非抢占的,所以如果当前executor上还运行着某个callback,那么必须等前一个跑完才行。
非Timer:按照pp的约束进行,每次到了pp就拉一批callback进来,然后跑完一个跑下一个。
下图是在某个pp点对于各种任务优先级的判断标准,在某个pp,优先查看timer,再按照sub-server-cli的顺序去调度任务。知道下一个pp
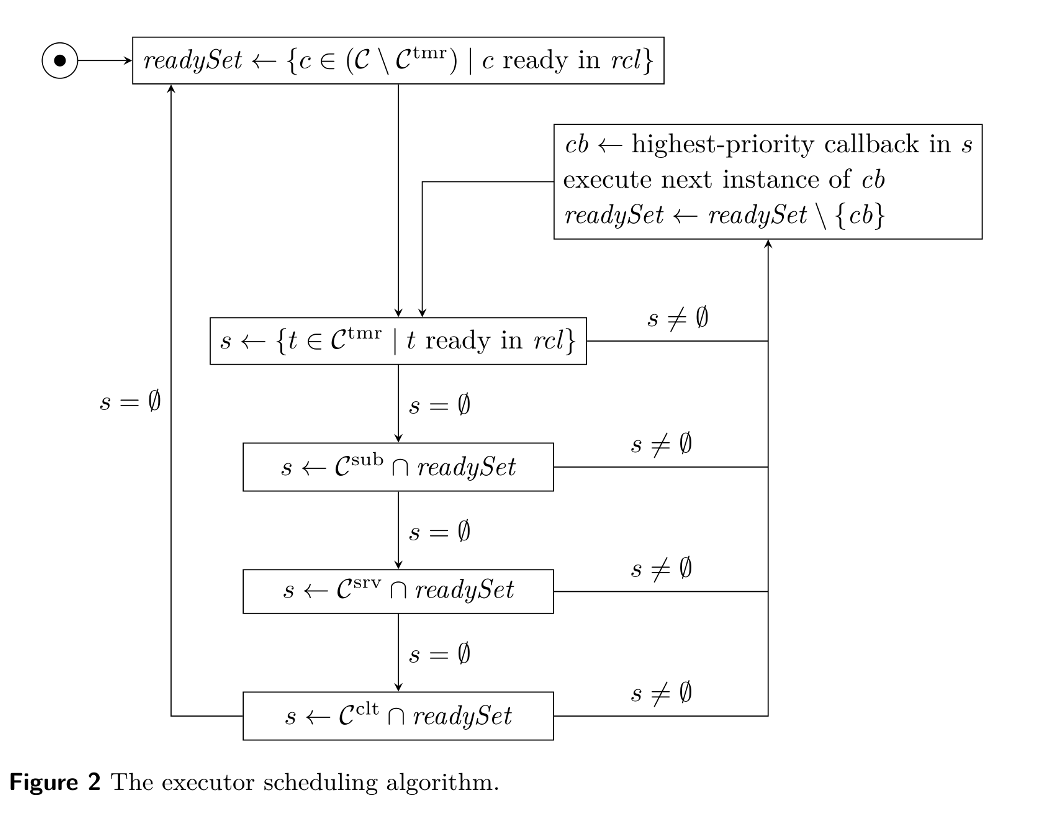
PP调度机制对实时的影响 #
1/对于timer来说,他需要等待executor上当前执行的callback执行完,这里引入了时延
2/对于非timer任务来说,一方面,他何时进入executor的调度器,是需要等待pp才能进入调度的,另一方面,需要考虑timer的处理时间
3/对于调度器来说,实际上给定了一个调度顺序:timer-sub-srv-clt,而这会导致排序在后面的类型的callback的延迟。
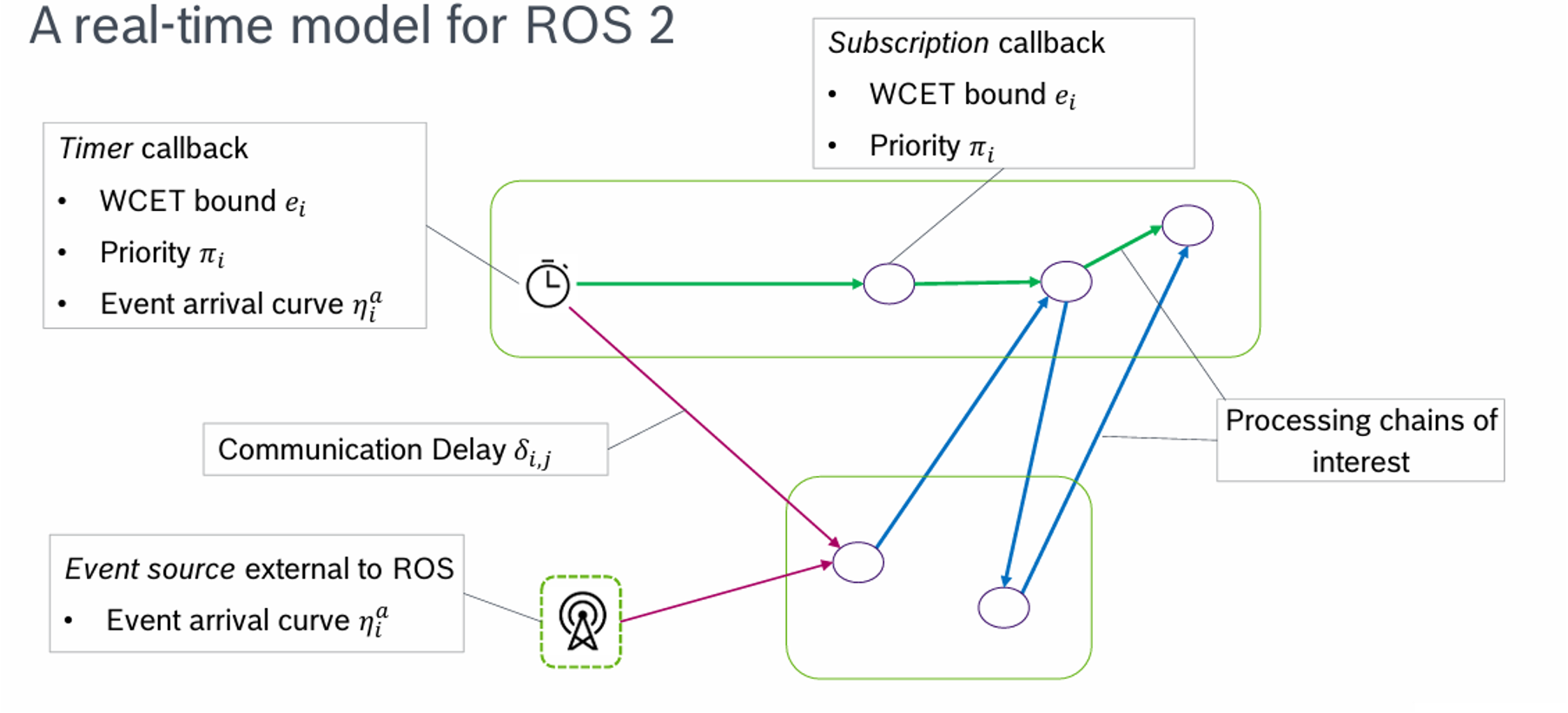
CPA分析方式(Compositional Performance Analysis) #
在这种分析方式的假设中,task互相依赖,他们构成了DAG(有向无环图)
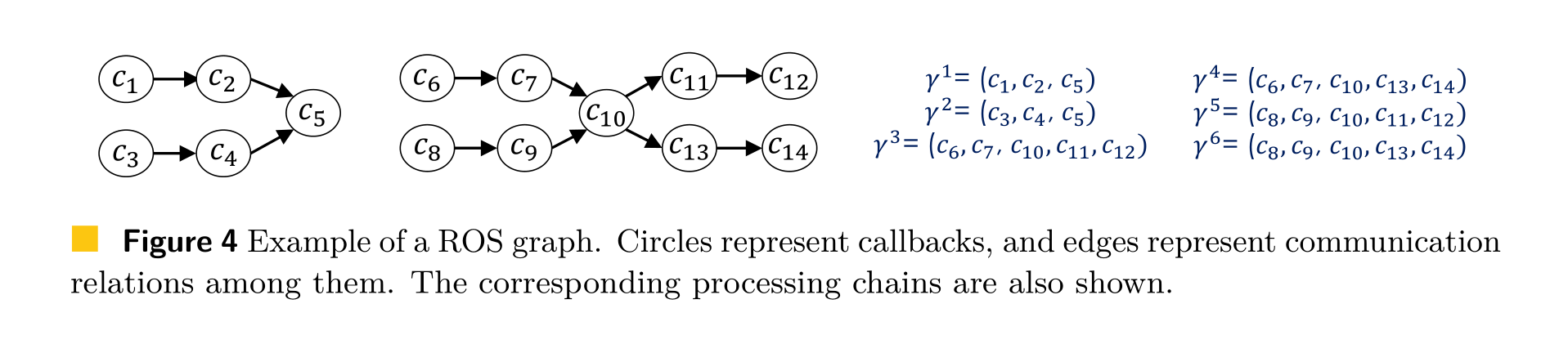
- Processing chain(处理链)概念 对于一个图上面的路径,构成一个链 比如下面的这两个callback(图中表示为c)构成的DAG图,右边是处理链
- Arrive curve(到达曲线) \[ η^e(∆) \]
这个概念用于表示对任意的区间∆,[t,t + ∆)区间内到达的事件数量上限
说人话就是,用于描述事件到达的规律
源回调:通常来源于比如传感器的数据,比如什么激光雷达啦这种,通常一个处理链是从一个源回调开始的
非源回调:在一个源回调之后产生的后续的回调事件。
Arrival-Curve Propagation (到达曲线传播)
举个例子就是下边两张图
最开始的事件产生了一个源回调,他有一个到达曲线 而在这个源回调唤起下游的回调的过程中,下游回调也会存在对应的到达事件,并根据这个时延,给出一个到达曲线
这个就是到达曲线传播
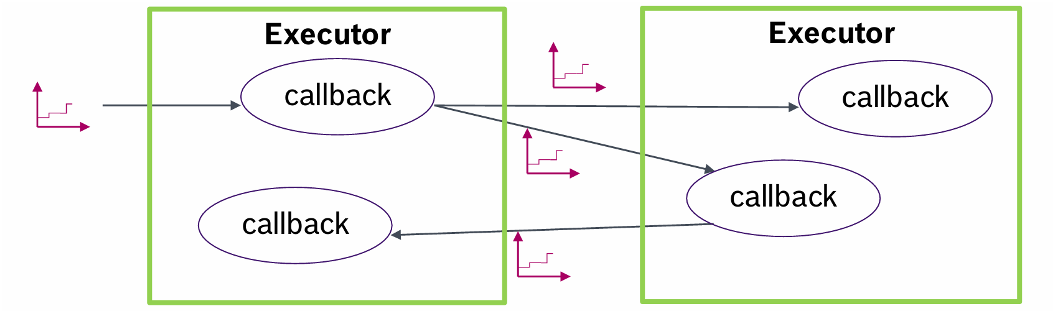
除此之外还需要考虑传播时延等等参数,下面这个例子我觉得还是比较形象得描述了整个系统
RBF和SBF #
简单来说,RBF是一段时间(通常是指开始到某个任务)内对于CPU的需求量,而SBF则是一段时间的供给量。需求量等于供给量的时候,这个任务才完成,那么这个时间点就是某个任务的响应时间。
- RBF 对于每个callback,如果令ei表示某个callback的最坏执行时间
那么有 \[ rbf_i(∆)= η_i^a(∆) * e_i \]
对于某个callback集合C* 有 \[ RBF(C^*,∆)= \sum_{c_i∈C^*}{rbf_i(∆)} \]
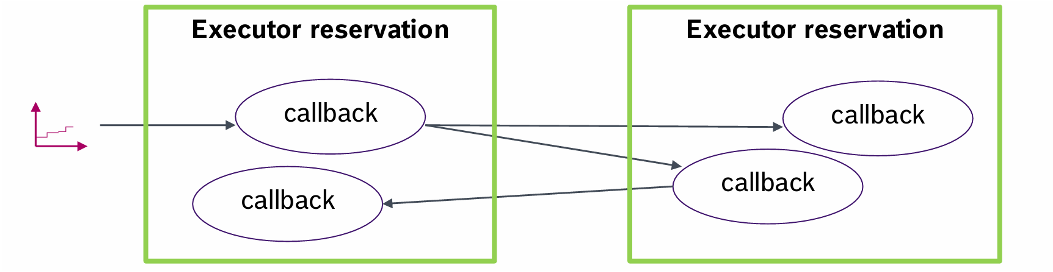
- SBF函数 在这里他试图使用了一个server的方法,给每个线程配了一个预留服务器(reservation)给他一定的带宽预算和执行周期,转换成一个周期性任务。
sbf函数则表示在某个时间间隔内能够提供的最小服务量
响应时间分析 #
在RBF和SBF的基础上(条件就是RBF等于SBF,请求的计算量要等于供给的计算量),他给出了以下几个概念的响应时间
- 源回调
- 定时器回调
- 非定时器的基于PP的回调
- 子链
源回调 #
响应时间为 \[ sbf_k(A+R_i^*(A)) = rbf_i(A+1) \]
这里A表示,在这个时刻这个callback才释放(他存在一个最初的抖动,比如传感器的数据到达存在一个抖动,这很正常),而 \[ R_i^*(A) \] 表示一个需要计算出来的时间点,在这个时间点,满足了计算需求函数和计算供给函数相等。
timer回调 #
\[ sbf_k(A+R_i^*(A)) = rbf_i(A+1) + RBF(hp_k(c_i),A+R_i^*(A)-e_i+1)+B_i \]在上述的基础上 算上了更高优先级的执行时间RBF,这里A+R-ei+1则是给定了响应时间R的前提下,最晚的开始执行时间 以及由于低优先级的过程(但是不可抢占)导致的延迟Bi
非timer回调 #
\[ sbf_k(A+R_i^*(A)) = rbf_i(A+1) + RBF(C_k^tmr,A+R_i^*(A)-e_i+1) + RBF(C_k^oth,A+R_i^*(A)-e_i-X+1) \]这里则考虑进去了 除了定时器的其他回调和定时器的回调两种 前者还需要考虑polling point的时延(他必须在这个点之后才能开始调度) 后者跟timer的一致
处理链 #
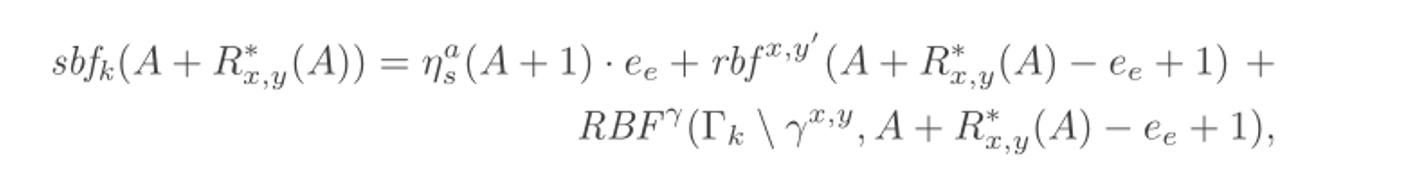
这里的xy表示从x到y的一段子链
这里分为三个部分
自干扰:在有向无环图上,x的callback可能导致y的callback的多次被调用
子链内部干扰:子链的某个callback唤醒的下游callback可能不在这条子链上,但是仍然抢占了服务器。
子链外部干扰:其他子链也可能占用服务器
Automatic Latency Management for ROS 2: Benefits, Challenges, and Open Problems #
ROS的实时化遇到的挑战(也跟组件化遇到的问题类似): #
1、 ROS采用了一大堆的他人写的组件,而最终的集成者,缺少对这些组件的深入了解,这点和传统的实时分析是有很大差别的,传统的实时分析起码能够知道各个组件的详细情况。因此,集成者很难去做ROS的实时化问题。
2、反过来,实时性分析的工作也不能让单个组件的编写者来搞,很多组件的实时性参数(比如WCET)取决于用例的参数(比如一个矩阵乘法中,矩阵的规模参数),这些用例的参数是只有最终的集成者才知道的。所以单个组件的编写者,他也不知道最后这个组件要运行多少时间
3、ROS通常用在机器人的环境下,是面对动态环境的情况,很难使用静态分析解决。(比如一个目标识别,在空旷的环境下的识别负载和密集环境下的识别负载也都不同,而这取决于场景)
ROS实时化(latency manager)需要满足的目标 #
1、 Form does not follow function(原谅我没看懂这个词)但他的目标大概是说,处理链可能包括多个进程,不能只考虑单个的进程,而需要考虑全局的优化
2、不能比改了之前更差,改之前是个简单的CFS调度器(按我的理解那时候还没有EEVDF塞到内核中去),他不能实时性更差
3、兼容性问题,ROS的生态而言,他的用户肯定不希望为了用ROS的实时性,再去弄个打了patch的补丁,所以限制了在进程层面能够选择的调度器。
4、同样的,不能期望现有的ROS组件进行大幅度的改写以适应实时性要求,所以也不能更改大量的ROS社区组件 (反正就是,这也不能改,那也不能改)
5、不要依赖于昂贵的前期静态分析(传统的实时经常会做静态分析),因为这要求系统集成者有丰富的实时的知识
6、需要考虑到环境因素的变化(正如前面挑战里面的第三条说的那样)
7、在发生过载的情况下(这是免不了的),可以让某些任务按照最大可能交付甚至直接不运行的模式进行工作
8、这个latency manager不需要太多的计算资源,尤其是可能存在过载的情况下(这也要求了不能考虑最优但昂贵的算法,而是使用次优的算法)
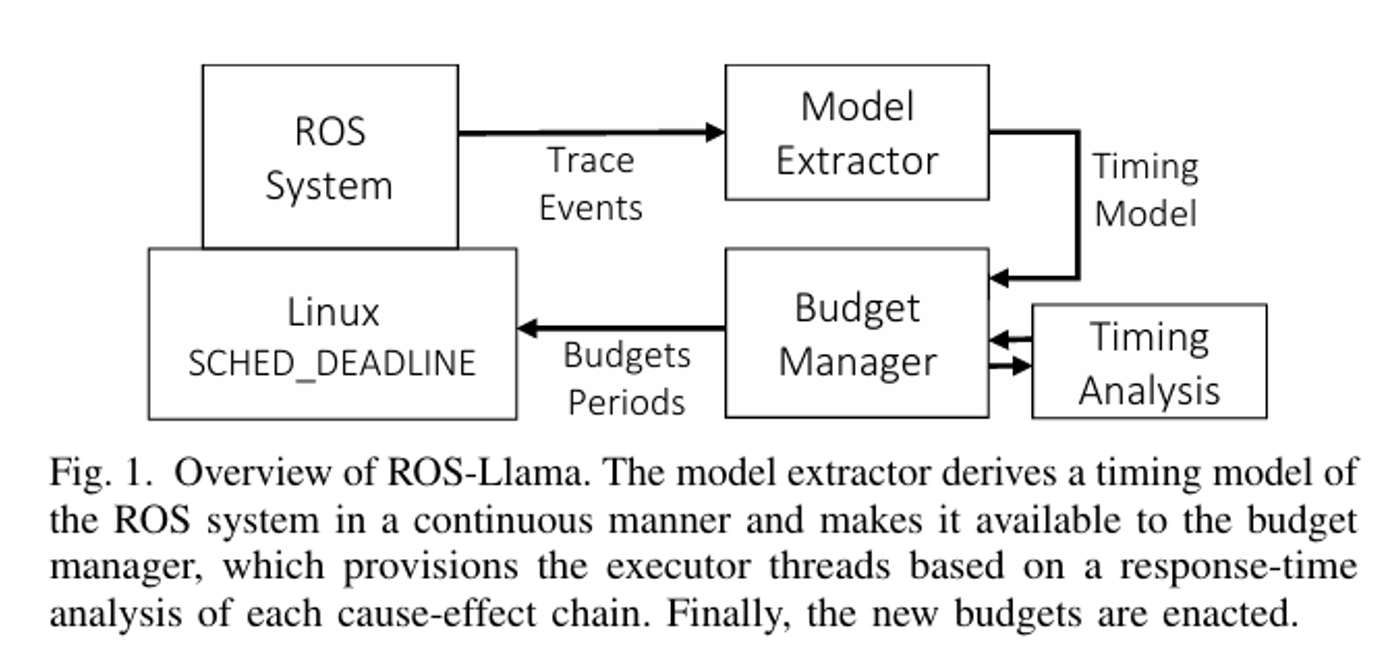
所以作者设计了一个latency manager,取名为ROS-Llama
为了满足上面的设计需求,必须做三件事: 1、提取ROS系统的模型 2、可以根据提取的模型,计算出需要给线程的配额配置线程 3、让线程按照设计的配额进行工作
系统架构是这样的(看上去也比较简单) 在一个运行的ROS系统之外,增加了一个model extractor(模型提取器),用于完成目标1 并把模型给Budget manager用于分析,以完成目标2
目标3则使用Linux SCHED_DEADLINE算法 (所以他这里实际决策的是给不同executor所在的服务器按照EDF给多少配额的问题)
Model extractor(主要就是用来收集ROS系统的信息,用于后续的决策) #
在注册新的回调函数的时候,会收集 Type Topic Identifier(实际上就是回调函数的虚拟地址)
它跟踪事件流来构建callback的activate图 每个事件包括 类型 原始的线程 两个时间戳(全系统的global时钟,用于表示事件到达时间,另一个是每个线程的处理时长,用于表明这个callback的处理时延) 其他的事件特定数据
最后,会在某个callback完成的时候,更新这个callback的到达时间曲线和执行时间曲线。
Budget manager #
根据model extractor给出的信息,每隔6秒,使用一个启发式迭代搜索的方法给出新一轮的调度配置(6秒应该是这个计算量比较大,太短的间隔CPU消耗比较严重)
其根据的工作也是前面一篇论文给出的响应时间分析所给出的sbf函数
启发式的方法分为两步:
1、第一步确定初始值 2、在初始值的基础上调整

- 确定初始值
他的做法实际上是根据查看过去horizon窗口内的信息来做决策的(右边的horizon设定为过去10s内的信息)
第一个for循环设定了某个executor的正常需要的带宽bandwidth
第二个for循环,第六行,needed相当于在过去的horizon窗口内还欠的处理能力(rbf是需要的CPU处理能力,而sbf是能够提供的,其差值就是horizon窗口内欠的)
加上这些内容之后,如果超过了100%的CPU带宽,就degrade,也就是把不满足的任务变成best-effort的了
算上这些调整之后,把这个值作为初始值
- 在初始值的基础上调整

看最外面的while循环是根据chain latency来调整的就知道,这个微调是根据某个处理链上的时间约束来判断某条链是否能满足约束
这里第四行的RT(c)表示当前实际的response-time bound
而RT100%(C)表示假定给予了100%带宽情况下的响应时间
换句话说这个d(e)表示真实的响应时间相比于100%带宽情况下响应时间的延迟
随后根据这个d(e)的降序来进行executor的排序(也就是说超过响应时间越多的,给他更高的判断权重)
按照5%的带宽占比,不断地增加给这个executor的带宽直到满足chain的约束或者超过100%的CPU带宽引发degrade