MCS在qemu运行下的偶发性bug #
在rel4中bug的现象和调试记录汇总(供参考 #
- 20250109
发现了该问题存在

- 20250116 尝试判断该问题触发的原因,目前的判断是可能是某一次的时钟中断之后的操作不合理(因为确实按照频率而言远比之前的错误触发频率要低得多,应该是时钟中断带来的的偶发性问题,而不是如同之前的错误一样) 原本是期望2-3-2-3-2-3,但是在某一次变成了3-2。于是和期望不符,就报错了。
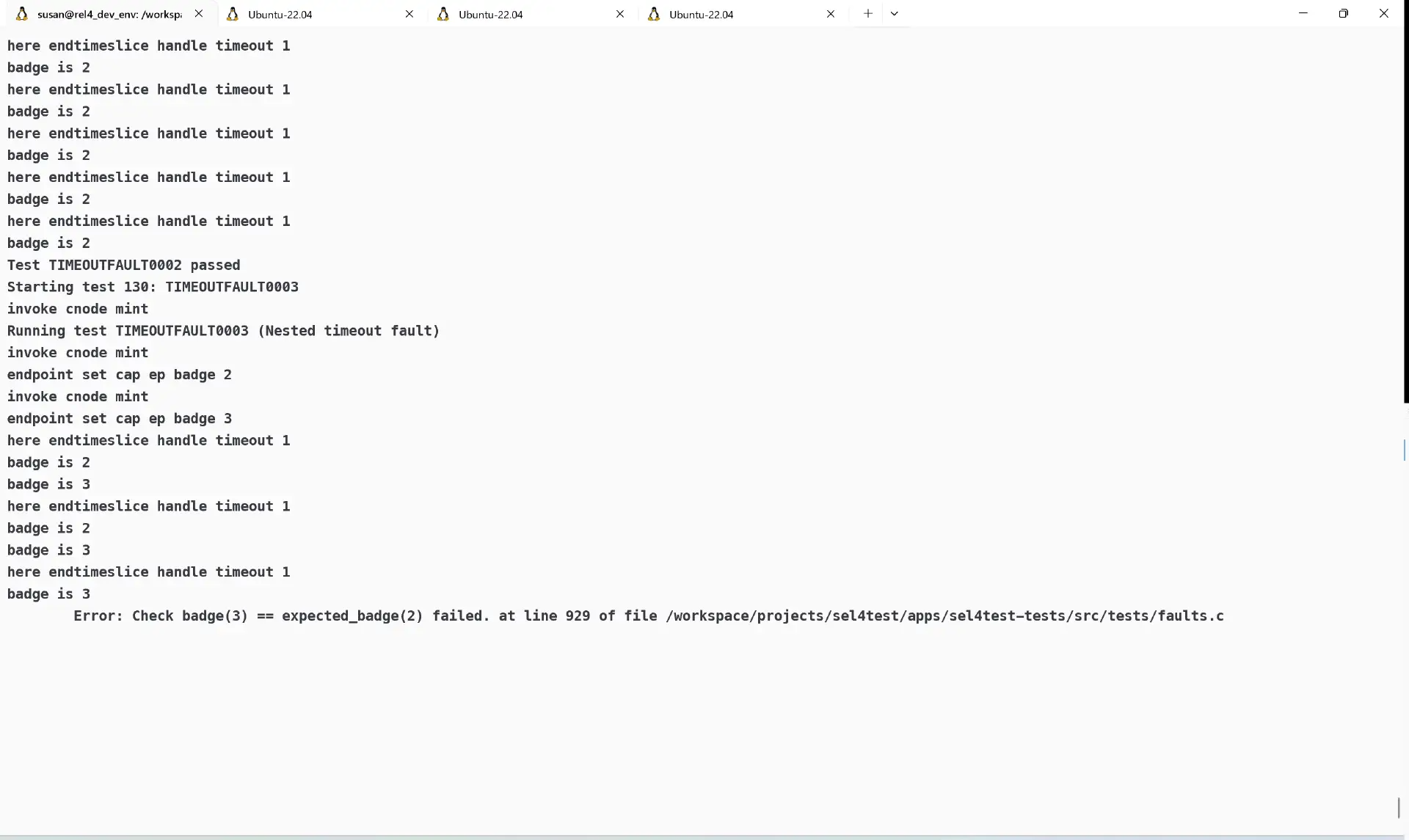
- 20250224 之前一直以为是,timeout fault的处理有问题。这次查看了,发现出错的地方远在此之前 顺带一提,需要注意timeoutfault0003的名字叫nested timeout fault就是嵌套的意思。
查看之前的bug,上面左边是错误的输出,右边是正常工作的输出,这个log是在调度器调度的进程发生切换的时候打印出来的,发现错误的少发生了一次进程切换。 而这个地方的判定条件是当前的action是SchedulerAction_ChooseNewThread就走进去。但是这里没走进去。 至于设置这里的时候,只有一个地方,是在rescheduleRequired这里。 不过调用reschedule required的地方就多了。(检查了一圈,没发现少写了reschedule required,除了多核的ipi) (注:后续尝试中,认为,上述少发生一次进程切换实际上是由于在sched_context的某次refill_ready判定的时候没有通过导致的)
另外,我需要补充说明这个timeoutfault0003的(按照我理解的)逻辑 他创建了两个线程,一个server,一个proxy,分别执行timeout_fault_server_fn和timeout_fault_client_fn,并进行一定的通信,按照注释来说,是期望client将自己的时间全都送给server,server在那边while循环,直到超时。 按照逻辑这时候应该使用timeout handler去进行操作。
- 20250519 这次尝试我不求甚解,打算直接暴力修复,简单来说,把所有涉及到MCS相关的函数直接再用C函数替换回去最开始,我尝试了以下几个函数 commitTime schedule sc.sc_sporadic refill_budget_check 但是这里面需要修改的函数数量就多了。(盲目替换不可取) 并且遇到如下问题: schedule等函数需要使用调度器的那些sched enqueue等函数,但是,因为更新过了新版本的sel4调度器,所以直接塞回去还遇到除了链接器之外的一大堆问题,直接整确实太不容易了。
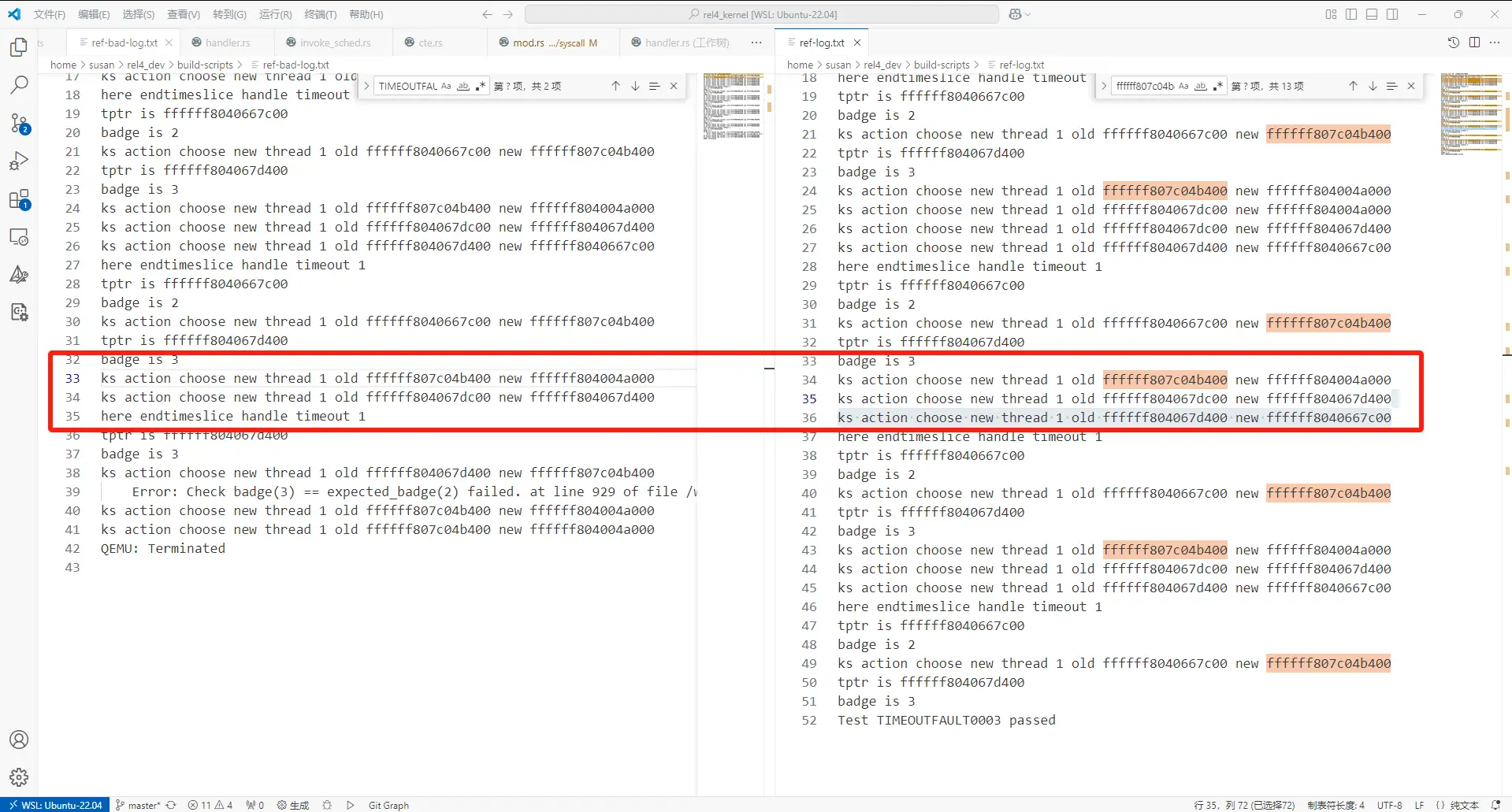
我后来转换了思路,因为这个测例本身使用的系统调用是不多的,并且,其他测例已经给整个系统趟过一圈雷了,所以,需要做的事情,是筛选出来整个timoutfault0003整个的关键路径替换,再去逐一测试 我查找了他在这里使用的handle syscall,除了sys_call之外使用的具体的syscall,并试图按照跑过的路径,进行排查。 但是在替换handlerecv的时候,又遇到了额外的各类问题。 这是目前的尝试
在sel4下同样的bug出现情况 #
感谢李心宇的发现,在sel4中存在相关的bug触发情况
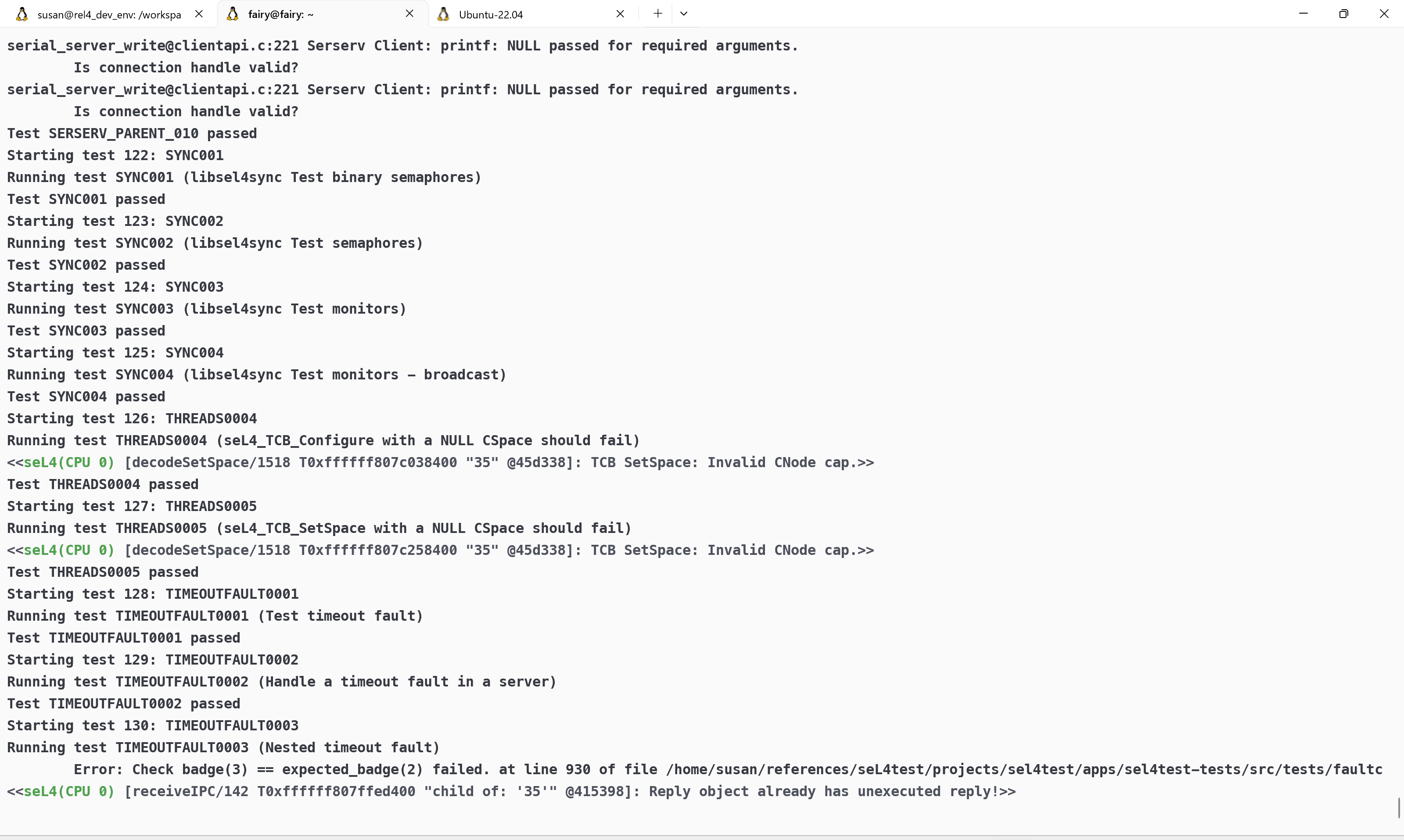
相关资料查阅 #
由上述内容可得,这并不是我实现的bug,后续查找相关资料得知
我看到了相关的帖子报告在QEMU环境中存在时间不准的问题 https://lists.sel4.systems/hyperkitty/list/devel@sel4.systems/thread/UROZ6FZRCB2KA5M2VIMI5HOD43NDKAPO/
顺着指引,我找到了相关的pr seL4/ci-actions#233
也就是说,这是由于QEMU的时间不够稳定导致的
解释如下:
Because the qemu emulation isn’t cycle accurate, the clock can be observed to skip ahead in large chunks based on scheduling of the host machine. One way that I’ve seen that seems to work around this slightly is by taking multiple sample points and discarding outliers. EG, if you want to implement a 50ms delay, you break it up into 10 5ms delays, and so any big jumps can only affect 10% of the total blocking time. I don’t have a good way to apply this to the core time accounting in MCS, but it may be possible to use it to write more robust tests.
对于触发过程相关代码和触发原理的推测(供参考) #
1.尝试修改时钟频率
首先,我试图修改reset_timer函数的参数来更改时钟中断的频率,并统计时钟中断频率对该事件触发的影响。
但该方案是错误的,虽然我测试得到的结果(没测试完,但是已知前提是错的,没必要测试了),看上去能够支持频率越高,bug触发频率越低的这个结论,但是实际上并非如此(下面说,倒是花了我不少时间去测试)。不过为什么该测试能够这么显著,我觉得要么就是测试次数不够,要么就是,这点偏差也是属于正常
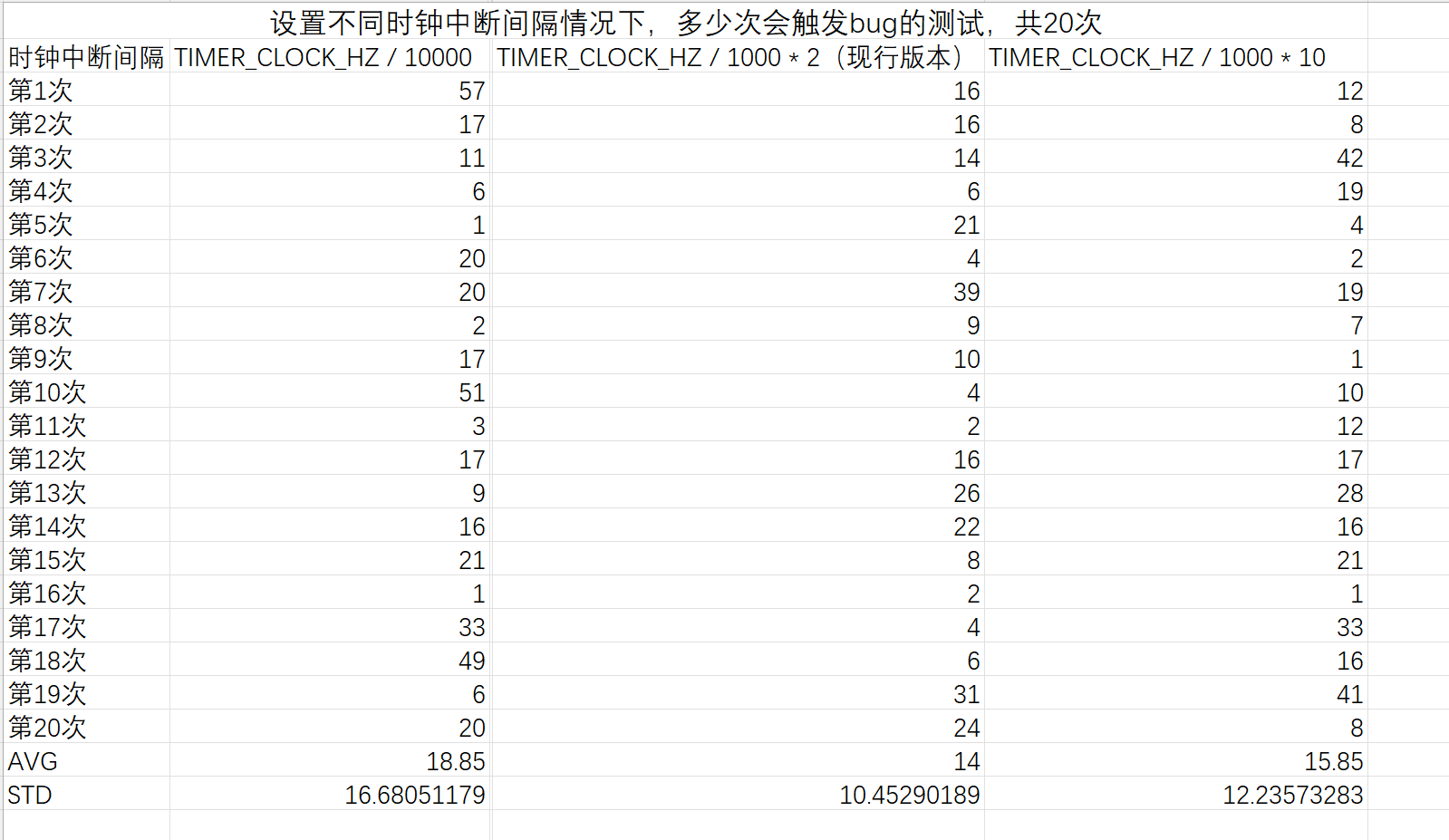
另外,概率分布不能这么算。如果某个事件(这里头显然是mcs这个bug)的发生概率为p,那么连续n-1次不触发bug并在第n次触发概率,应该是(1-p)的(n-1)次乘以p。这并不是一个平滑的值,直接算均值方差,显然是毫无意义,所以这个测试从头到尾,全都是错的,没啥意义。
2.尝试直接阅读理解代码
对于代码
- 关于时钟中断相关 因为前面说了,可能跟时钟中断频率和准确性相关。因此,一个是设置时钟中断。 在mcs下,会执行
timer.ack_deadline_irq()
set_reprograme(true)
并在schedule()中
设置
if get_reprogram(){
set_next_interrupt();
set_reprogram(true)
}
这里的set_next_interrupt代码是跟mcs的算法高度相关且耦合的。 ss算法在某个任务使用了一段时间之后,都会安排一个重填,这个重填,包括在何时重填,以及重填多少的问题。 这里会判定当前任务的下一次重填和其他任务(在release_queue中被记录)中的最早的重填记录。
- 关于bug触发相关
我可以观察到的现象是在endTimeslice中会试图尝试调整队列。可以观察到的一点是,这里有个postpone函数,在触发了错误的时候,timeoutfault0003,一次都不会触发postpone,但是其他情况,可能触发,可能不会触发。
对于这个错误机制,判断如下:SS算法由于QEMU的时间不准确,会导致超时运行了一段时间,这导致了根据SS算法,需要延后下一次重填的时间,这会导致,根据算法,这导致了调度顺序的错误,从而发生了上述的现象。