1. 说明 #
seL4 中 smp 设计较为简单,主要是通过一个 big kernel lock 确保 kernel 和单核情况下表现几乎一致,不会出现竞争的情况。
seL4 smp 设计说明可参考 seL4 smp
关于 big kernel lock, seL4 认为对于微内核来说,内核大锁并不会过多影响效率. big kernel lock
如上所说,seL4 的 SMP 避免了内核中竞态和中断嵌套的情况,主要实现的部分如下
- 每个核心独立数据的管理,例如任务队列
- 调度逻辑,除了调度当前核心的任务,还需要操作别的核心的任务
- ipi 通信和相应处理函数的实现
- 内核大锁的实现
- smp 相关的初始化过程的实现
- smp 对 mcs 的支持实现
2. 每个核心的独立实例 #
在 smp 模式中,有一些实例是每个核心一份,独有的。之前在单核模式下,我们可以将其作为全局变量不加区分,但是在多核模式下这部分需要修改。
seL4 中该部分实现如下
// kernel/include/model/smp.h
typedef struct smpStatedata {
archNodeState_t cpu;
nodeState_t system;
PAD_TO_NEXT_CACHE_LN(sizeof(archNodeState_t) + sizeof(nodeState_t));
} smpStatedata_t;
extern smpStatedata_t ksSMP[CONFIG_MAX_NUM_NODES];
// 其中 archNodeState 如下,在 smp 模式下,这段编译时会变成 struct smpStatedata_t {}
NODE_STATE_BEGIN(archNodeState)
/* TODO: add ARM-dependent fields here */
/* Bitmask of all cores should receive the reschedule IPI */
NODE_STATE_DECLARE(word_t, ipiReschedulePending);
#ifdef CONFIG_ARM_HYPERVISOR_SUPPORT
NODE_STATE_DECLARE(vcpu_t, *armHSCurVCPU);
NODE_STATE_DECLARE(bool_t, armHSVCPUActive);
#if defined(CONFIG_ARCH_AARCH32) && defined(CONFIG_HAVE_FPU)
NODE_STATE_DECLARE(bool_t, armHSFPUEnabled);
#endif
#endif
#if defined(CONFIG_BENCHMARK_TRACK_UTILISATION) && defined(KERNEL_PMU_IRQ)
NODE_STATE_DECLARE(uint64_t, ccnt_num_overflows);
#endif /* defined(CONFIG_BENCHMARK_TRACK_UTILISATION) && defined(KERNEL_PMU_IRQ) */
NODE_STATE_END(archNodeState);
// 和 reL4 移植目标相关的也就 ipiReschedulePending 这一个字段,hypervisor 我们暂时应该不考虑
// nodeState_t 比较重要,数据结构如下
NODE_STATE_BEGIN(nodeState)
NODE_STATE_DECLARE(tcb_queue_t, ksReadyQueues[NUM_READY_QUEUES]);
NODE_STATE_DECLARE(word_t, ksReadyQueuesL1Bitmap[CONFIG_NUM_DOMAINS]);
NODE_STATE_DECLARE(word_t, ksReadyQueuesL2Bitmap[CONFIG_NUM_DOMAINS][L2_BITMAP_SIZE]);
NODE_STATE_DECLARE(tcb_t, *ksCurThread);
NODE_STATE_DECLARE(tcb_t, *ksIdleThread);
NODE_STATE_DECLARE(tcb_t, *ksSchedulerAction);
#ifdef CONFIG_KERNEL_MCS
NODE_STATE_DECLARE(tcb_queue_t, ksReleaseQueue);
NODE_STATE_DECLARE(ticks_t, ksConsumed);
NODE_STATE_DECLARE(ticks_t, ksCurTime);
NODE_STATE_DECLARE(bool_t, ksReprogram);
NODE_STATE_DECLARE(sched_context_t, *ksCurSC);
NODE_STATE_DECLARE(sched_context_t, *ksIdleSC);
#endif
#ifdef CONFIG_HAVE_FPU
/* Current state installed in the FPU, or NULL if the FPU is currently invalid */
NODE_STATE_DECLARE(user_fpu_state_t *, ksActiveFPUState);
/* Number of times we have restored a user context with an active FPU without switching it */
NODE_STATE_DECLARE(word_t, ksFPURestoresSinceSwitch);
#endif /* CONFIG_HAVE_FPU */
#ifdef CONFIG_DEBUG_BUILD
NODE_STATE_DECLARE(tcb_t *, ksDebugTCBs);
#endif /* CONFIG_DEBUG_BUILD */
在 reL4 中,我们将 archNodeState 和 nodeState 两个结构体中的用到的字段直接放在了 SmpStateData 中,和 seL4 中的 smpStatedata_t 是等效的。
// sel4_task/src/scheduler.rs
pub struct SmpStateData {
/// Number of pending IPI (Inter-Processor Interrupt) reschedule requests.
pub ipiReschedulePending: usize,
/// Array of ready queues for each domain and priority level.
pub ksReadyQueues: [tcb_queue_t; CONFIG_NUM_DOMAINS * CONFIG_NUM_PRIORITIES],
/// Bitmap representing the presence of ready queues at the L1 level for each domain.
pub ksReadyQueuesL1Bitmap: [usize; CONFIG_NUM_DOMAINS],
/// Bitmap representing the presence of ready queues at the L2 level for each domain and priority level.
pub ksReadyQueuesL2Bitmap: [[usize; L2_BITMAP_SIZE]; CONFIG_NUM_DOMAINS],
/// Index of the currently executing thread.
pub ksCurThread: usize,
/// Index of the idle thread.
pub ksIdleThread: usize,
/// Action to be taken by the scheduler.
pub ksSchedulerAction: usize,
/// TODO: MCS support
/// FPU support
pub ksActiveFPUState: usize,
pub ks_fpu_restore_since_switch: usize,
}
为了兼容 smp 和 非 smp,通过下面函数根据编译选项返回不同的值
// 以 get_idle_thread 为例
#[inline]
/// Get the idle thread, and returns a mutable tcb reference to the idle thread.
pub fn get_idle_thread() -> &'static mut tcb_t {
unsafe {
#[cfg(feature = "enable_smp")]
{
convert_to_mut_type_ref::<tcb_t>(ksSMP[cpu_id()].ksIdleThread)
}
#[cfg(not(feature = "enable_smp"))]
{
convert_to_mut_type_ref::<tcb_t>(ksIdleThread)
}
}
}
进一步优化的话,就是全部使用 ksSMP,可以兼容单核和多核的情况。
3. SMP 调度相关移植 #
该部分介绍 nomcs 调度策略下,和 smp 相关的代码移植。nomcs 调度策略比较简单,smp 相关的主要是通知别的核心重置调度和任务。
3.1 任务队列变化 #
seL4 中 SMP 模式下,在 SCHED_APPEND,SCHED_ENQUEUE 中需要增加 remoteQueueUpdate
#define SCHED_ENQUEUE(_t) do { \
tcbSchedEnqueue(_t); \
remoteQueueUpdate(_t); \
} while (0)
在 reL4 中,我们使用 update_queue 实现 remoteQueueUpdate,核心是将需要 reschedule 的核心加到 ipiReschedulePending map 中
fn update_queue(&self) {
use super::scheduler::{ksCurDomain, ksSMP};
use sel4_common::utils::{convert_to_type_ref, cpu_id};
unsafe {
if self.tcbAffinity != cpu_id() && self.domain == ksCurDomain {
let target_current =
convert_to_type_ref::<tcb_t>(ksSMP[self.tcbAffinity].ksCurThread);
if ksSMP[self.tcbAffinity].ksIdleThread == ksSMP[self.tcbAffinity].ksCurThread
|| self.tcbPriority > target_current.tcbPriority
{
ksSMP[cpu_id()].ipiReschedulePending |= BIT!(self.tcbAffinity);
}
}
}
}
// ipiReschedulePending 在 schedule() 函数中生效,本质上就是通知其他核心 reschedule
// sel4_task/src/scheduler.rs:865
#[cfg(feature = "enable_smp")]
unsafe {
do_mask_reschedule(ksSMP[cpu_id()].ipiReschedulePending);
ksSMP[cpu_id()].ipiReschedulePending = 0;
}
// do_mask_reschedule 发送 reschedule ipi 请求,通知别的核心重新调度
3.2 重置当前任务 #
当操作别的核心的 tcb 时,可能会破坏其正在运行的 tcb,因此需要发送通知别的核心重置当前调度,避免调度到被破坏的 tcb.
seL4 中在如下几个地方会进行 remoteTCBStall 操作,reL4 里也是一样。
// src/object/objecttype.c:182
case cap_thread_cap: {
if (final) {
tcb_t *tcb;
cte_t *cte_ptr;
tcb = TCB_PTR(cap_thread_cap_get_capTCBPtr(cap));
SMP_COND_STATEMENT(remoteTCBStall(tcb);)
cte_ptr = TCB_PTR_CTE_PTR(tcb, tcbCTable);
unbindNotification(tcb);
}
}
// src/object/tcb.c:808
exception_t decodeTCBInvocation(word_t invLabel, word_t length, cap_t cap,
cte_t *slot, bool_t call, word_t *buffer)
{
/* Stall the core if we are operating on a remote TCB that is currently running */
SMP_COND_STATEMENT(remoteTCBStall(TCB_PTR(cap_thread_cap_get_capTCBPtr(cap)));)
...
}
// 还有一些是在 MCS 相关函数里,目前还没移植
remoteTCBStall 我们在 ipi 通信的实现里介绍,主要功能就是提醒另一个核心当前的任务被修改了,需要重新检查其状态,判断是否可以运行。
4. IPI 核间通信 #
基于 IPI (Inter-Processor Interrupt,核间中断) 实现的核间通信为 SMP 设计提供了核间同步机制。seL4 中用了两个中断号对应两种通信方式。
- irq_remote_call_ipi: 通知别的核心执行对应的函数
- irq_reschedule_ipi: 通知别的核心 reschedule
IPI 的实现主要分为
- 中断机制的实现
- IPI 中断处理函数的实现
- remote call 对应函数的实现
4.1 IPI 中断机制的实现 #
无论是 riscv 还是 aarch64 架构,都提供了 IPI 实现的硬件基础,但是二者有点不同,实现起来也不一样。
4.1.1 riscv 的 IPI 通信实现 #
riscv 中,一个核心可以给另一个发送软件中断,这个中断属于 CLINT,而不是 PLIC,和 Timer 中断是并列关系。
该机制存在一个问题,就是没有中断号,只能维护一个全局数组,储存每个核心当前的 IPI IRQ。发送方将 IRQ 填到数组中,然后发送软件中断。接收方收到中断号查看数组中对应的 IRQ。为了保持数据统一性,需要发送方执行 fence 操作,确保接收方收到的是更新后的 IRQ。
具体实现如下
// kernel/src/arch/riscv/smp.rs
// irq 全局数组,每个核心对应一个 ipi irq number
static mut ipi_irq: [usize; CONFIG_MAX_NUM_NODES] = [IRQ_INVALID; CONFIG_MAX_NUM_NODES];
// ipi 发送函数
pub fn ipi_send_target(irq: usize, target: usize) {
let mask = BIT!(target);
let core_id = hart_id_to_core_id(target);
assert!(core_id < CONFIG_MAX_NUM_NODES);
unsafe {
// 设置对应核心的 ipi irq
ipi_irq[core_id] = irq;
}
fence(Ordering::SeqCst);
// 发送软件中断
sbi_send_ipi(mask);
}
// ipi 接收函数,就是读取 irq 全局数组
pub fn ipi_get_irq() -> usize {
unsafe {
assert!(!(ipi_irq[cpu_id()] == IRQ_INVALID && clh_is_ipi_pending(cpu_id())));
return ipi_irq[cpu_id()];
}
}
get_active_irq 是获取中断号的关键函数,进入中断处理函数后首先就需要获取中断号。smp 模式下,获取 ipi irq 也集成在这个函数中
pub fn get_active_irq() -> usize {
let mut irq = unsafe { active_irq[cpu_id()] };
if is_irq_valid(irq) {
return irq;
}
let sip = read_sip();
#[cfg(feature = "enable_smp")]
{
use sel4_common::arch::riscv64::clear_ipi;
if (sip & BIT!(SIP_SEIP)) != 0 {
irq = 0;
} else if (sip & BIT!(SIP_SSIP)) != 0 {
// 发现是软件中断,认为是 ipi
clear_ipi();
irq = ipi_get_irq();
// debug!("irq: {}", irq);
} else if (sip & BIT!(SIP_STIP)) != 0 {
irq = KERNEL_TIMER_IRQ;
} else {
irq = IRQ_INVALID;
}
}
}
4.1.2 aarch64 的 IPI 实现 #
目前只在 gic_v2 上实现了 IPI。总的来说,gic 专门为 SGI(Software Generated Interrupt) 预留了 16 个中断号,这些中断号是每个核的私有中断。这些中断和其他中断使用上没什么区别,因此无需像 riscv 一样,通过软件实现中断号的区分。我们需要实现的就是 ipi 发送函数。
//kernel/src/arch/aarch64/arm_gic/gic_v2/gic_v2.rs
#[allow(unused)]
pub fn ipi_send_target(irq: usize, target: usize) {
let val = irq << 0 | target << 16;
GIC_DIST.regs().sgi_control.set(val as u32);
}
smp 下,aarch64 get_active_irq 函数实现如下,由于 IPI 和其他中断号没有任何区别,因此无需做特别处理
pub fn get_active_irq() -> usize {
let irq = gic_int_ack();
if (irq & IRQ_MASK as usize) < MAX_IRQ {
unsafe_ops!(active_irq[cpu_id()] = irq);
}
let local_irq = unsafe_ops!(active_irq[cpu_id()]) & IRQ_MASK as usize;
let irq2 = match local_irq < MAX_IRQ {
true => local_irq,
false => IRQ_INVALID,
};
log::debug!("active irq: {}", irq);
irq2
}
4.2 中断处理函数 #
由于增加了 IPI 通信方式,因此在中断处理函数中,需要增加 IPI 处理函数。
// kernel/src/interrupt/handler.rs
#[cfg(feature = "enable_smp")]
IRQState::IRQIPI => {
crate::smp::ipi::handle_ipi(irq, true);
}
handle_ipi 实现如下,根据 irq 分别执行对应处理函数
pub fn handle_ipi(irq: usize, irq_path: bool) {
match irq {
IRQ_REMOTE_CALL_IPI => unsafe {
crate::arch::handle_remote_call(
remote_call,
get_ipi_arg(0),
get_ipi_arg(1),
get_ipi_arg(2),
irq_path,
);
},
IRQ_RESCHEDULE_IPI => {
sel4_task::reschedule_required();
#[cfg(target_arch = "riscv64")]
unsafe {
core::arch::asm!("fence.i", options(nostack, preserves_flags));
}
}
_ => sel4_common::println!("handle_ipi: unknown ipi: {}", irq),
}
}
handle_remote_call 还需要根据 remote_call 的 ID 执行对应的函数,后续介绍。
IRQ_RESCHEDULE_IPI 触发重新调用请求,调用 reschedule_required() 函数。
4.3 remote call 对应函数的实现 #
4.3.1 remote call 发送函数 #
remote call 分为以下几类
// 通用
pub enum ipi_remote_call {
IpiRemoteCall_Stall = 0,
IpiRemoteCall_switchFpuOwner,
}
// aarch64 独有的
pub enum ipi_remote_call {
// in invalidateTLBByASIDVA
IpiRemoteCall_InvalidateTranslationSingle,
//findFreeHWASID invalidateTLBByASID
IpiRemoteCall_InvalidateTranslationASID,
// not used
IpiRemoteCall_InvalidateTranslationAll,
// invokeIRQHandler_AckIRQ
IpiRemoteCall_MaskPrivateInterrupt,
}
因此移植的目标很简单,实现上述所有的 remote call 即可。remote call 的实现有点类似 syscall,都是将函参填到指定位置,然后发送请求。无非 ipi remote call 是将函参填到全局数组变量中,然后发送 ipi 中断触发函数调用。按照上述分析,实现如下。
// remote call 基础发送函数
pub fn do_remote_mask_op(
func: ipi_remote_call,
arg0: usize,
arg1: usize,
arg2: usize,
mask: usize,
) {
let mut mask2 = mask;
mask2 &= !(crate::BIT!(cpu_id()));
if mask2 != 0 {
unsafe {
// 填入函参
ipi_args[0] = arg0;
ipi_args[1] = arg1;
ipi_args[2] = arg2;
remote_call = func;
total_core_barrier = mask2.count_ones() as usize;
}
fence(Ordering::SeqCst);
// 发送 ipi 中断
ipi_send_mask(IRQ_REMOTE_CALL_IPI, mask2, true);
// ipi wait 同步机制,另一个核心调用 ipi_wait 后才会继续执行
ipi_wait();
}
}
// ipi 发送函数基本一样,只是函参不同,以 remote_tcb_stall 为例
pub fn remote_tcb_stall(tcb: &tcb_t) {
// TODO: mcs support
if tcb.tcbAffinity != cpu_id() && tcb.is_current() {
do_remote_stall(tcb.tcbAffinity);
// 和之前提到的 update_queue 功能类似,发送 reschedule 请求给其他核心
tcb.update_ipi_reschedule_pending();
}
}
4.3.2 remote call 处理函数 #
根据 remote call 类型,执行不同的处理函数,如下
pub fn handle_remote_call(
call: ipi_remote_call,
arg0: usize,
arg1: usize,
arg2: usize,
irq_path: bool,
) {
if crate::smp::clh_is_ipi_pending(cpu_id()) {
match call {
ipi_remote_call::IpiRemoteCall_Stall => {
crate::smp::ipi::ipi_stall_core_cb(irq_path);
}
ipi_remote_call::IpiRemoteCall_switchFpuOwner => unsafe {
crate::arch::fpu::switch_local_fpu_owner(arg0);
},
ipi_remote_call::IpiRemoteCall_InvalidateTranslationSingle => {
invalidate_local_tlb_va_asid(arg0)
}
ipi_remote_call::IpiRemoteCall_InvalidateTranslationASID => {
invalidate_local_tlb_asid(arg0)
}
ipi_remote_call::IpiRemoteCall_MaskPrivateInterrupt => {
crate::interrupt::mask_interrupt(arg0 != 0, arg1)
}
_ => {
sel4_common::println!(
"handle_remote_call: call: {:?}, arg0: {}, arg1: {}, arg2: {}",
call,
arg0,
arg1,
arg2
);
}
}
crate::smp::clh_set_ipi(cpu_id(), 0);
crate::smp::ipi::ipi_wait();
}
}
重点介绍下 ipi_stall_core_cb,其他 callback 较为简单,可自行阅读源码。
ipi_stall_core_cb 实现如下,功能是暂停当前任务,切换到 idle thread,进一步重新触发调度。如果当前任务还可以运行,则继续执行该任务,如果不可执行,则避免调度到该任务。
// seL4 中是 ipiStallCoreCallback
pub fn ipi_stall_core_cb(irq_path: bool) {
let thread = sel4_task::get_currenct_thread();
// 如果当前处于内核中并且不是中断处理函数
// 处于内核态时,会屏蔽所有内核态中断,因此 syscall 获取锁时也会检查是否存在 ipi call
if super::clh_is_self_in_queue() && !irq_path {
if thread.tcbState.get_tsType() == ThreadState::ThreadStateRunning as u64 {
sel4_task::set_thread_state(thread, ThreadState::ThreadStateRestart);
}
// 暂停当前任务,切换到 idle 线程
thread.sched_enqueue();
switch_to_idle_thread();
// TODO: mcs support
sel4_task::set_ks_scheduler_action(SCHEDULER_ACTION_RESUME_CURRENT_THREAD);
// 完成 ipi 处理 flag
super::clh_set_ipi(cpu_id(), 0);
#[cfg(target_arch = "riscv64")]
{
crate::arch::ipi_clear_irq(IRQ_REMOTE_CALL_IPI);
}
// 通知发送者 ipi 请求处理完成,对端可以继续
ipi_wait();
// 相当于获取锁,避免出现竞态
while super::clh_next_node_state(cpu_id()) != super::lock::clh_qnode_state::CLHState_Granted
{
crate::arch::arch_pause();
}
fence(Ordering::SeqCst);
sel4_task::activateThread();
crate::arch::restore_user_context();
} else {
thread.sched_enqueue();
// TODO: mcs support
switch_to_idle_thread();
sel4_task::set_ks_scheduler_action(SCHEDULER_ACTION_RESUME_CURRENT_THREAD);
}
}
5. 锁的实现 #
seL4 中使用内核大锁,确保始终只有一个核心位于内核。锁的设计逻辑如下图所示。
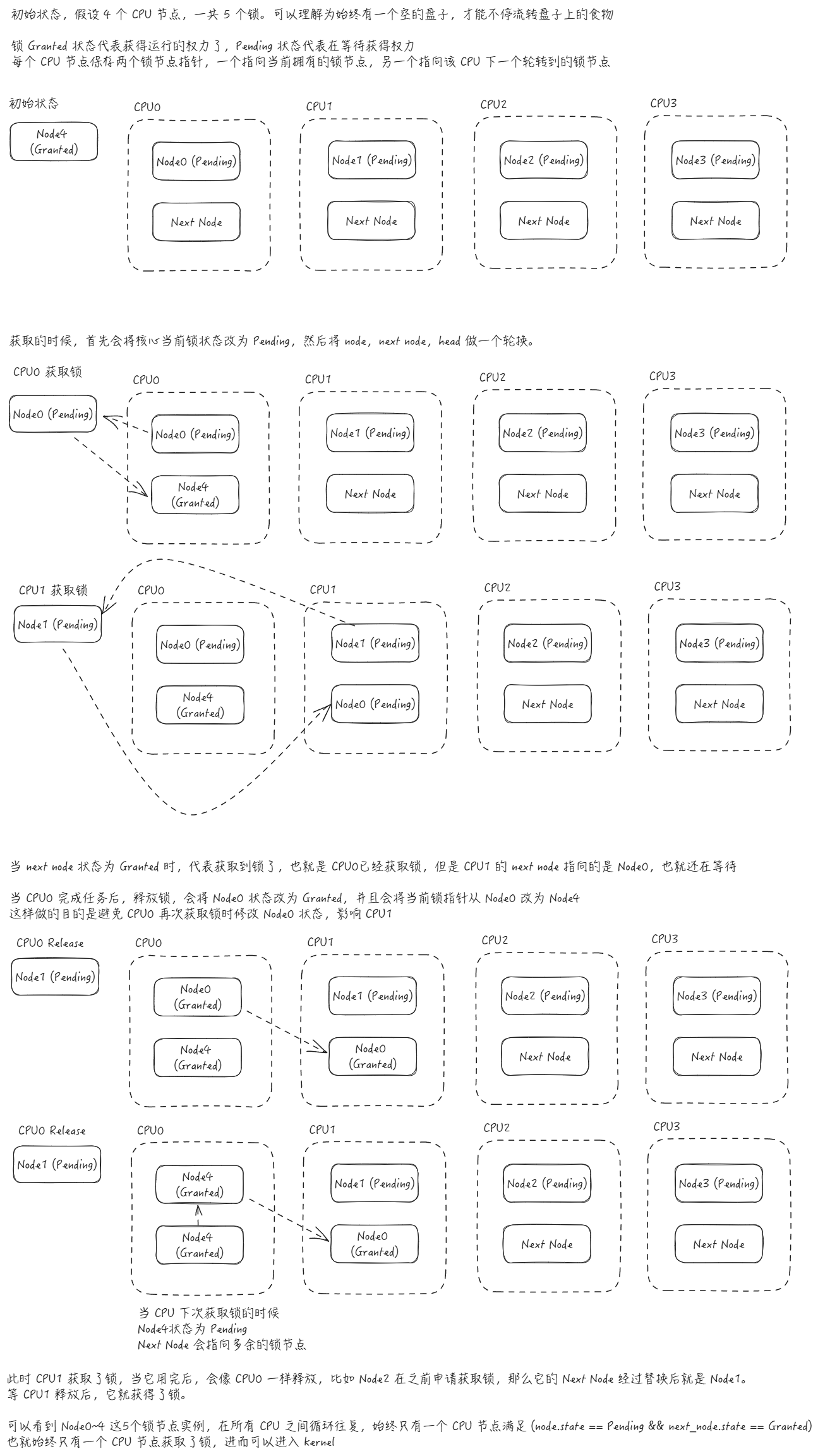
可以看到,无论有几个核心,都会轮流获得锁的控制权,等到上一个核心 release 之后,排在它之后的核心才会获取锁的控制权。
锁的实现如下
/// 节点的状态,Pending 代表尝试获取锁,在等待,Granted 代表已经获取了锁
#[derive(PartialEq, Copy, Clone)]
pub enum clh_qnode_state {
CLHState_Granted = 0,
CLHState_Pending,
}
/// 锁节点的实例,存储当前节点的状态
#[repr(align(64))]
#[derive(Copy, Clone)]
struct clh_qnode {
state: clh_qnode_state,
}
/// 每个核心锁相关的实例
#[repr(align(64))]
struct clh_qnode_p {
// 当前锁状态,使用 AtomicPtr,确保数据同步
node: AtomicPtr<clh_qnode>,
// 其实是队列中上一个核心锁的状态
next: AtomicPtr<clh_qnode>,
// 该核心是否有 ipi 请求
ipi: usize,
}
/// 内核大锁
#[repr(align(64))]
pub struct clh_lock {
// 锁的节点,数量是 核心数量 + 1, 可以理解谁获取那个多个节点,谁就获得了锁
nodes: [clh_qnode; CONFIG_MAX_NUM_NODES + 1],
// 核心实例,所以数量和核心数量相同
node_owners: [clh_qnode_p; CONFIG_MAX_NUM_NODES],
// 多的那个锁节点的指针,初始时就是 granted 状态,哪个节点获取了它,就获得了锁
head: AtomicPtr<clh_qnode>,
}
最关键的实现是 clh_lock_acquire
pub fn acquire(&mut self, cpu: usize, irq_path: bool) {
unsafe {
// 将该核心的当前锁状态设置为 Pending
self.node_owners[cpu]
.node
.load(Ordering::Acquire)
.as_mut()
.unwrap()
.set_state(clh_qnode_state::CLHState_Pending);
// 尝试获取下 head 中存储的锁,其实是上一个执行 acquire 操作的核心的锁,这样自然根据执行 acquire 的时间自然形成了队列
let mut prev_node: Option<&mut clh_qnode> = None;
while prev_node.is_none() {
// 原子操作,替换自己的锁和 head 中存储的锁
let raw_ptr: *mut clh_qnode = self.head.swap(
self.node_owners[cpu].node.load(Ordering::Acquire),
Ordering::Relaxed,
);
self.node_owners[cpu].next.store(raw_ptr, Ordering::Release);
// 如果能找到锁的实例,那就是替换成功,会自动退出 While 循环
prev_node = raw_ptr.as_mut();
// 等待时如果发现有 ipi 操作请求,直接执行,无需等到下次 ipi 中断再执行了
if self.is_ipi_pending(cpu) {
super::ipi::handle_ipi(IRQ_REMOTE_CALL_IPI, irq_path);
}
crate::arch::arch_pause();
}
// 查看队列中,上一个核心的锁状态,如果锁状态变成 Granted,代表上一个核心执行了 Release 操作,也就代表当前核心可以获得锁了
while self.next_node_value(cpu) != clh_qnode_state::CLHState_Granted {
// 同样,发现有 ipi 操作请求,直接执行,无需等待获取锁
if self.is_ipi_pending(cpu) {
super::ipi::handle_ipi(IRQ_REMOTE_CALL_IPI, irq_path);
}
crate::arch::arch_pause();
}
}
}
/// Release 操作简单,将当前核心锁状态改为 Granted
#[inline]
pub fn release(&mut self, cpu: usize) {
fence(Ordering::Release);
unsafe {
self.node_owners[cpu]
.node
.load(Ordering::Acquire)
.as_mut()
.unwrap()
.set_state(clh_qnode_state::CLHState_Granted);
// 将上一个核心的锁设置为当前核心的锁,避免该核心再次 acquire 是设置锁的状态,影响到了下一个核心获取锁的操作
let next = self.node_owners[cpu].next.load(Ordering::Acquire);
self.node_owners[cpu].node.store(next, Ordering::Release);
}
}
6. 启动代码 #
smp 启动时需要对每个核心进行初始化,从核的初始化比主核简单很多。同时还需要为每个核心创建 idle 线程,初始化核间通信中断等等。
启动时,会根据当前核心的 ID 判断是主核还是从核,主核相比之前,增加了锁的初始化、IPI 中断初始化、release 从核的操作
// seL4 src/arch/arm/kernel/boot.c
SMP_COND_STATEMENT(clh_lock_init());
SMP_COND_STATEMENT(release_secondary_cpus());
...
#ifdef ENABLE_SMP_SUPPORT
setIRQState(IRQIPI, CORE_IRQ_TO_IRQT(getCurrentCPUIndex(), irq_remote_call_ipi));
setIRQState(IRQIPI, CORE_IRQ_TO_IRQT(getCurrentCPUIndex(), irq_reschedule_ipi));
#endif
如果发现 CPU 是从核,会调用 try_init_kernel_secondary_core,该函数会等到主核释放从核后,开始初始化操作。代码比较易懂,如下
BOOT_CODE static bool_t try_init_kernel_secondary_core(void)
{
/* need to first wait until some kernel init has been done */
while (!node_boot_lock);
/* Perform cpu init */
init_cpu();
for (unsigned int i = 0; i < NUM_PPI; i++) {
maskInterrupt(true, CORE_IRQ_TO_IRQT(getCurrentCPUIndex(), i));
}
// 注册当前核心的中断,方便后续中断处理函数判断中断类型
setIRQState(IRQIPI, CORE_IRQ_TO_IRQT(getCurrentCPUIndex(), irq_remote_call_ipi));
setIRQState(IRQIPI, CORE_IRQ_TO_IRQT(getCurrentCPUIndex(), irq_reschedule_ipi));
/* Enable per-CPU timer interrupts */
setIRQState(IRQTimer, CORE_IRQ_TO_IRQT(getCurrentCPUIndex(), KERNEL_TIMER_IRQ));
// 后续会调用 schedule 函数,进入 idle 线程,会释放锁
// 所以从核是一个个启动的
NODE_LOCK_SYS;
clock_sync_test();
ksNumCPUs++;
init_core_state(SchedulerAction_ResumeCurrentThread);
return true;
}
主核会等到所有核心启动完成后,才会完成初始化工作,整个初始化流程结束。
7. MCS 相关的移植 #
7.1 MCS Node State 的移植 #
MCS 模式下,会多出一些 node_state,smp 需要将其从一个核心扩展到每个核心,主要是这部分的移植工作。
#[cfg(feature = "kernel_mcs")]
pub ksReleaseQueue: tcb_queue_t,
#[cfg(feature = "kernel_mcs")]
pub ksConsumed: time_t,
#[cfg(feature = "kernel_mcs")]
pub ksCurTime: time_t,
#[cfg(feature = "kernel_mcs")]
pub ksReprogram: bool,
#[cfg(feature = "kernel_mcs")]
pub ksCurSC: usize,
#[cfg(feature = "kernel_mcs")]
pub ksIdleSC: usize,
这些改动主要如下,就是把 node_state 从直接引用变为加上 NODE_STATE!()
- #[cfg(feature = "kernel_mcs")]
- unsafe {
- ksCurSC = get_currenct_thread().tcbSchedContext;
- ksConsumed = 0;
- ksReprogram = true;
- ksReleaseQueue.head = 0;
- ksReleaseQueue.tail = 0;
- ksCurTime = timer.get_current_time();
+ #[cfg(feature = "kernel_mcs")]
+ {
+ SET_NODE_STATE!(ksCurSC = get_currenct_thread().tcbSchedContext);
+ SET_NODE_STATE!(ksConsumed = 0);
+ SET_NODE_STATE!(ksReprogram = true);
+ SET_NODE_STATE!(ksReleaseQueue = tcb_queue_t {head: 0, tail: 0});
+ SET_NODE_STATE!(ksCurTime = timer.get_current_time());
}
7.2 耦合地方的移植 #
还有一些地方,条件是 SMP 且 非MCS 模式,这部分在引入 MCS 后需要做特别处理,例如
#[cfg(all(feature = "enable_smp", not(feature = "kernel_mcs")))]
TCBSetAffinity,
在 MCS 时,这个 message label 是不存在的,因此需要加入上面条件。
还有其他一些类似的地方,搜索这个条件即可找到。
8. Node State 宏 #
Node State 使每个 CPU 核心的全局状态,例如任务队列,当前任务等等变量。
单核时,这些变量就是字面意义的全局变量,而多核是,由于每个核心维护一套变量,因此用数组的形式储存。
seL4 中使用 C 的宏定义,可以灵活的在单核和多核中切换,如下
#ifdef ENABLE_SMP_SUPPORT
#define MODE_NODE_STATE_ON_CORE(_state, _core) ksSMP[(_core)].cpu.mode._state
#else
#define MODE_NODE_STATE_ON_CORE(_state, _core) _state
#define NODE_STATE(_state) NODE_STATE_ON_CORE(_state, getCurrentCPUIndex())
在 rust 中,无法像 C 的宏定义这么灵活自由,我们用 marco_rules 尽量替代。
我们定义了如下宏规则
#[cfg(feature = "enable_smp")]
#[macro_export]
macro_rules! NODE_STATE {
($field:ident) => {
unsafe { $crate::ksSMP[sel4_common::utils::cpu_id()].$field }
};
}
#[cfg(not(feature = "enable_smp"))]
#[macro_export]
macro_rules! NODE_STATE {
($field:ident) => {
unsafe { $crate::$field }
};
}
/// seL4 NODE_STATE_ON_CORE, get the core node state field
#[cfg(feature = "enable_smp")]
#[macro_export]
macro_rules! NODE_STATE_ON_CORE {
($cpu:expr, $field:ident) => {
unsafe { $crate::ksSMP[$cpu].$field }
};
}
#[cfg(not(feature = "enable_smp"))]
#[macro_export]
macro_rules! NODE_STATE_ON_CORE {
($cpu:expr, $field:ident) => {
unsafe { $crate::$field }
};
($field:ident) => {
unsafe { $crate::$field }
};
}
# 由于 rust 中无法像 C 一样,直接替换宏定义,只能多增加 SET 系列宏用于赋值
/// SET_NODE_STATE, set the core node state field
#[cfg(feature = "enable_smp")]
#[macro_export]
macro_rules! SET_NODE_STATE {
($field:ident = $val:expr) => {
unsafe { $crate::ksSMP[sel4_common::utils::cpu_id()].$field = $val; }
};
}
#[cfg(not(feature = "enable_smp"))]
#[macro_export]
macro_rules! SET_NODE_STATE {
($field:ident = $val:expr) => {
unsafe { $crate::$field = $val; }
};
}
/// SET_NODE_STATE_ON_CORE, set the specific core node state field
#[cfg(feature = "enable_smp")]
#[macro_export]
macro_rules! SET_NODE_STATE_ON_CORE {
($cpu:expr, $field:ident = $val:expr) => {
unsafe { $crate::ksSMP[$cpu].$field = $val; }
};
}
#[cfg(not(feature = "enable_smp"))]
#[macro_export]
macro_rules! SET_NODE_STATE_ON_CORE {
($cpu:expr, $field:ident = $val:expr) => {
unsafe { $crate::$field = $val; }
};
($field:ident = $val:expr) => {
unsafe { $crate::$field = $val; }
};
}